
Agora que você já sabe o que é Machine Learning, vamos entender um pouco mais do papel que esse profissional desempenha.
Dentro das carreiras de dados o Machine Learning Engineer foi o último que surgiu, cuidando da parte de monitoramento e colocando os modelos em produção, estruturando e deixando mais fácil do Data Scientits fazer o deploy.
Para ficar mais fácil vamos começar analisando as etapas de um projeto de Data Science para melhor entendimento.
No primeiro momento é onde ocorre a questão e o entendimento de negócio, o cliente apresenta os problemas e a seguir é feito compreensão real da dor do cliente. Depois do entendimento das raízes dos problemas chegamos na fase de coleta de dados, onde ocorre bastante SQL, requisições e APIs espalhados em um único local. Após essa etapa é feita a limpeza de dados, onde se entende o que é problema sistêmico e o que é um problema intrínseco do negócio.
Depois é feito a exploração de dados, onde usam-se técnicas e estatísticas para entender o fenômeno que se está modelando através dos dados, nesse momento que se gera insights, para entender variáveis e o modelo que será melhor aplicado. Passando para etapa de modelagem que é onde o algoritmo começa aprender e se aplica transformações e separações para preparar os dados.
Dessa fase em diante começa o algoritmo de Machine Learning, onde aplicam-se os algoritmos para aprender o comportamento ou tarefa desejada, em seguida se faz a avaliação desse algoritmo separando o que é bom ou não e depois dessa análise de performance do modelo ele irá para a produção, onde passa para um ambiente Cloud para onde o dispositivo da internet consegue consumir as predições que o modelo fornece. A continuação desse processo é papel do Machine Learning Engineer. Obviamente o desenvolvimento em si não é tão simples quanto parece.
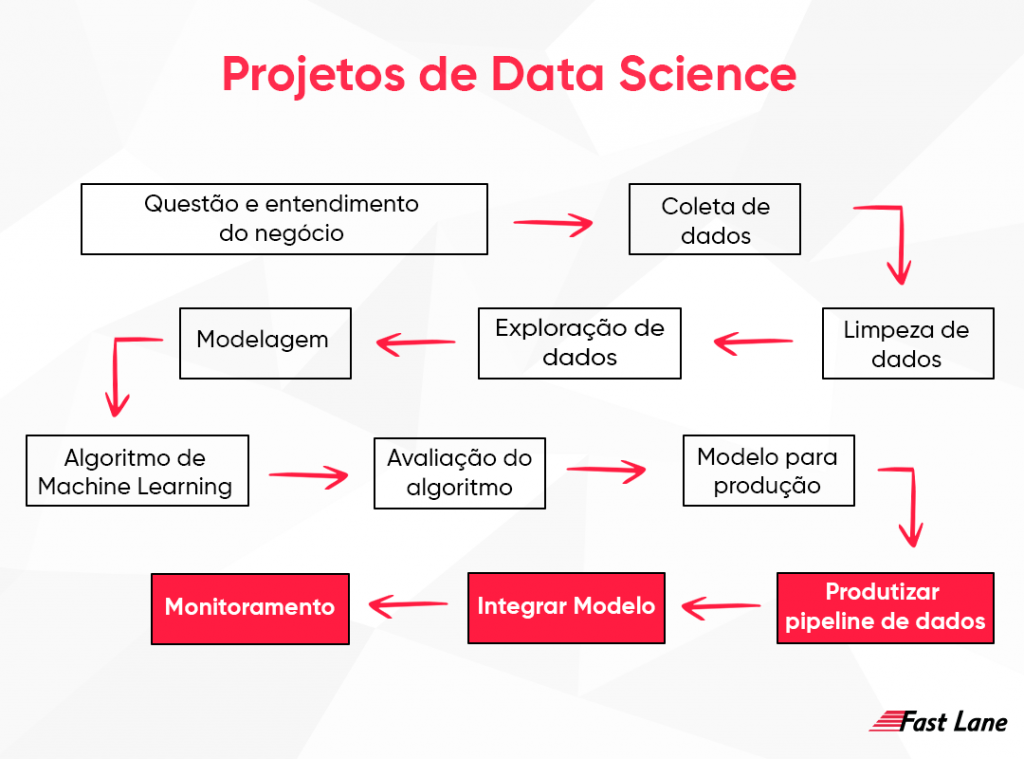
Responsabilidade do Machine Learning depois do processo
Tudo começa com a produtização do pipeline de dados, onde se pega todas as tarefas, desde a coleta de dados até modelo de produção, para se tornar um produto fácil escalável, fácil manutenção, lembre-se de sempre guardar de forma organizada para que outros profissionais trabalhem.
Depois de se tornar um produto vamos integrar o modelo, exemplo: frontend consome as predições dos seus modelos, sempre que o usuário entra e a página da home está carregando o frontend consome a predição do modelo e fala a propensão de produtos do cliente, logo não pode demorar para retornar se não torna o site mais lento, para isso precisamos integrar em outros sistemas respeitando os requisitos. Por último é necessário criar técnicas de monitoramento, onde se cria as métricas para saber se o modelo está acertando ou se os erros estão aumentando, como está a distribuição das variáveis, etc.
Explicando o processo
O Data Scientits coleta os dados, treina o modelo e após isso ele irá para produção para ser aplicado, a partir deste ponto começa o papel do Machine Learning.
Lembrando que os clientes podem consumir o resultado através de backend, website, aparelho móvel e IBA, para conectar as pessoas que precisam das predições com os modelos que o fornecem é necessário faz uma API (Ligação entre os dois mundos, cliente e serviço, conforme explicamos em nossas redes sociais) os clientes passam a fazer pedidos para API, ela irá interpretar a requisição e se tem permissão para acessar esses dados.
Os dados da API são dados não tratados, ou seja, os dados não vêm com as transformações que usamos lá no treinamento do modelo. Logo, é necessário mudar os dados RAW para a feature, assim será feita a predição.
Podemos usar de exemplo a seguinte ideia: uma pessoa tem o aplicativo e quer ver a predição do faturamento das lojas. Uma feature é a idade do usuário, quanto tempo a loja está aberta. Essa feature é guardada na Feature Store, onde se encontra várias feature, que os Data Scientits criaram para poder modelar e treinar os modelos de Machine Learning.
Dentro do Feature Store, nesse caso, nós encontraríamos dentro dele diversos dados, como a data em que a loja começou a operar. Então a API, vai para Feature Story e recupera as features solicitadas pelo modelo que foi treinado para fazer esta predição, e retorna para o modelo Machine Learning com o conjunto de feature, ele faz a predição e retorna para a API, que devolver a informação para o cliente.
Esse exemplo seria um processo simples, a diferença é que você tem as feature pré calculado dentro de uma Feature Store, que precisa ser atualizado sempre. *Feature Consumpotin, é o processo de consumir as Feature.
Para manter a feature store atualizada é necessário consultar o Data Warehouse, onde fica os dados modelados (feito pelo Data Engineer), para criar um feature e assim armazenar na feature store, esse processo é chamado de Feature Creation.
Fique com um modelo visual do exemplo.
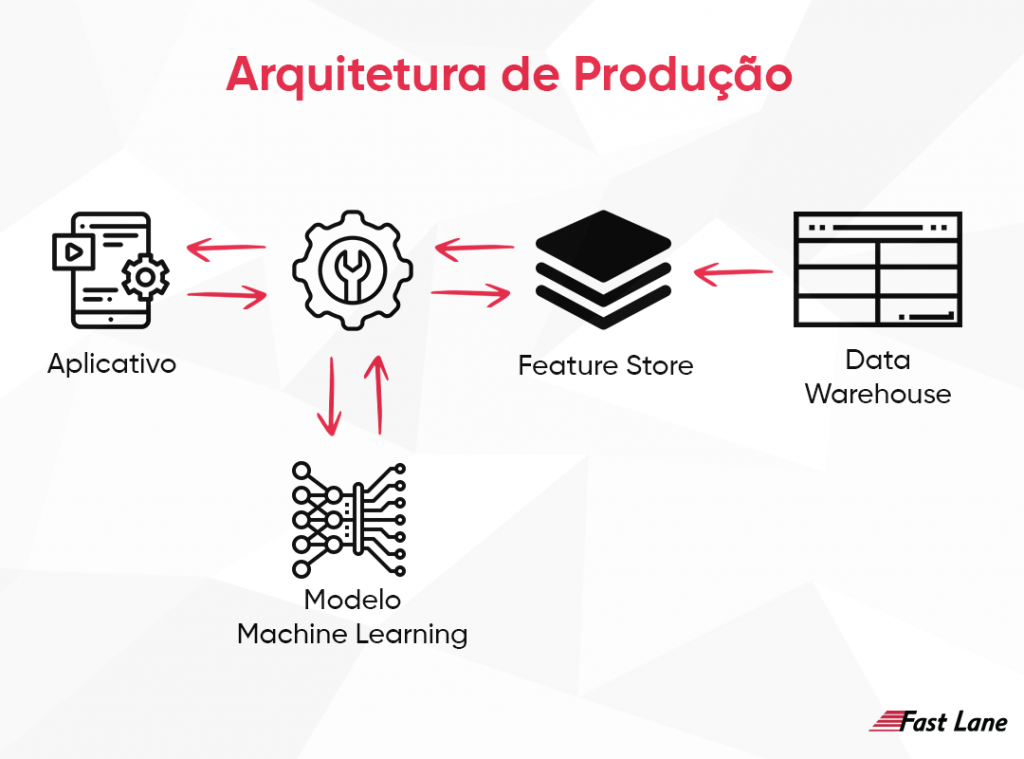
Essa imagem representa todo o papel do Machine Learning Engineer, voltado para produção e não desenvolvimento, ajudando os Data Scientits a colocar modelos em produção mais rápido.
O Machine Learning ajuda criando as classes onde os Data Scientits importam e reescrevem os métodos para fazer o treinamento, depois do modelo treinado e devolvido com todos os métodos usados e features criadas é aplicada em produção.
Esperamos que tenha ficado mais fácil de você entender como funciona o papel do Machine Learning Engineer, se tiver alguma dúvida, comentário ou sugestão ficaremos felizes em ajudar e responder. É importante lembrar que temos conteúdos rápidos e de grande ajuda em nossas redes sociais, lá também colocamos caixas de perguntas para ajudar no que for possível no seu caminho de conhecimento e aprendizado.
Escrito por Mayara Pimentel – com revisão final de Raphael Silva.